pwgen is a handy package that runs on Linux (among other systems). According to its description it “generates random, meaningless but pronounceable passwords. These passwords contain either only lowercase letters, or upper and lower case mixed, or digits thrown in. Uppercase letters and digits are placed in a way that eases remembering their position when memorizing only the word”. I use pwgen -1 for “one time only passwords” like when subscribing to mailing lists or web sites that require a username/password combination and I am not sure that I will stick with them. In other words, passwords that I fire and forget.
Unfortunately, it does not run under Windows, which is what I am working on some of these days. The code is pretty standard though, and with some minor tweaking, like borrowing a getopt(3) implementation and using srand(3)/rand(3) instead of /dev/urandom (Windows does have a similar capability) porting it to Windows was easy.
Having the source around is always handy! For those who do not want to do it themselves, here is a link to the (compiled with Digital Mars C++) binary: wpwgen.exe
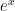 “, I said. “No” he replied, “I ask again, what does the logartihm do?”. A friend started to say something along the lines of the Wikipedia definition. “You tell me how it is calculated, but not what it stands for; why do we need it?”. He then proceeded asking us the value of the logarithm of some numbers:
“, I said. “No” he replied, “I ask again, what does the logartihm do?”. A friend started to say something along the lines of the Wikipedia definition. “You tell me how it is calculated, but not what it stands for; why do we need it?”. He then proceeded asking us the value of the logarithm of some numbers: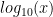
 “, one of us observed.
“, one of us observed. . He had 8 bit registers available only, so this limited counting up to 255 which did not suite the application he had at hand. So he began by simply having the value of a register representing
. He had 8 bit registers available only, so this limited counting up to 255 which did not suite the application he had at hand. So he began by simply having the value of a register representing  and reached to a generalized result of
and reached to a generalized result of  where a controls both the maximum count that can be held in the register and the expected error.
where a controls both the maximum count that can be held in the register and the expected error. . The expected error of n after n counts can be calculated from the formula
. The expected error of n after n counts can be calculated from the formula  .
.