The first book I ever bought from ISACA‘s bookstore, was Nigrini‘s book on Benford’s Law. Briefly stated the law says that in a series of numbers that occur while observing a phenomenon, numbers starting with 1 are more likely to occur than those starting with 2 which in turn are more likely to appear than those that start with 3 and so on up to numbers starting with 9.
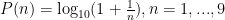
The law stands for other bases too.
I’ve had discussions about Benford’s Law applicability on email data over at twitter with Martijn Grooten, but never run any tests. A few hours back I had an interesting discussion with Theodore which reminded me of the law and so I decided to see whether it stands on a number series related to email. The easiest test I could run was on the length of the Subject: lines. Bellow what follows is a graph of Benford’s distribution and actual data from 376916 mails that passed a certain mail server during last week:

It seems that the length of subject lines follow the pattern. For the sake of speed I have omitted from the computation non-latin subject lines, which means that I have to recompute whenever I find a timeslot longer than 15 minutes. But then again if I am to find such a slot, I think I will try to see whether the message body size also follows a Benfordian distribution. It may be more difficult to verify though because of different mail servers imposing different limits on the size of messages sent and received by them. Oh wait, Sotiris just did that! The rest of the tests mentioned in Nigrini’s book are also worth a try.
So what do your logs say about subject lines’ length and Benford’s Law? Do they follow the pattern? I’d be glad to see your answer in the comments section.
PS: I see that there is now a second edition of Nigrini’s book about to be published!

The law stands for email sizes as well!
The same seems to hold true for message subjects of all archived messages of lists.hellug.gr mailing lists. I just ran a small Python script (a) to collect all subject lengths and dump them in JSON format, and a second one (b) to collect all counts with the same starting digit in one slot
(a) http://paste.lisp.org/display/127536
(b) http://paste.lisp.org/display/127537
The resulting starting-digit counts of 84261 messages were:
http://paste.lisp.org/display/127538
and they seem to fit pretty nicely around the P(x) curve:
http://twitpic.com/8ghjmw
Thanks for the effort. Given the multitude of email data withing your employer’s organization, it would be really useful if the Postmasters there could run some tests to explore the existence of Benfordian properties in email messages :)